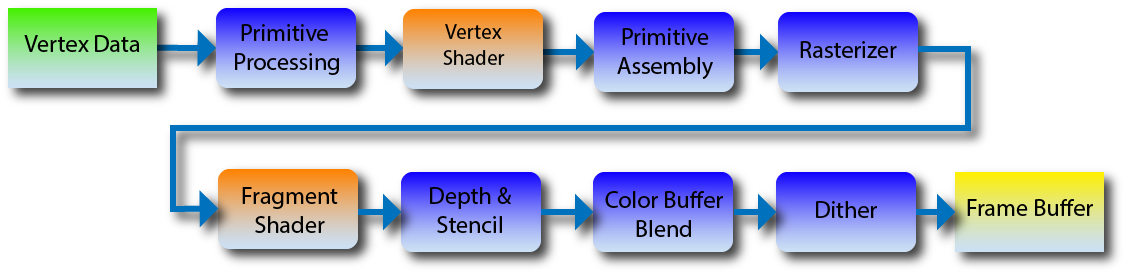
有栈协程切换原理
这篇应该是21年写的,当时在公司做分享的ppt,整理笔记翻到了,发出来当博客吧~
有栈协程介绍
有栈协程就是实现了一个用户态的线程,用户可以在堆上模拟出协程的栈空间,当需要进行上下文切换的时候,主线程只需要交换栈空间和恢复一些相关的寄存器的状态就可以实现一个用户态的线程上下文切换,没有了从用户态转换到内核态的切换成本,的执行也就更加高效 —- 知乎
有栈协程的好处
就后端开发来讲,有栈协程并没有提高程序的运行速度。 one event-loop per thread (IO multiplex) 比 one connection per coroutine 快得多,因为协程上下文切换反而增加了开销