有栈协程切换原理
目录
这篇应该是21年写的,当时在公司做分享的ppt,整理笔记翻到了,发出来当博客吧~
有栈协程介绍
有栈协程就是实现了一个用户态的线程,用户可以在堆上模拟出协程的栈空间,当需要进行上下文切换的时候,主线程只需要交换栈空间和恢复一些相关的寄存器的状态就可以实现一个用户态的线程上下文切换,没有了从用户态转换到内核态的切换成本,的执行也就更加高效 —- 知乎
有栈协程的好处
就后端开发来讲,有栈协程并没有提高程序的运行速度。 one event-loop per thread (IO multiplex) 比 one connection per coroutine 快得多,因为协程上下文切换反而增加了开销
但是使用协程,能帮助RD更容易的写出非阻塞的代码,对于多变的业务,再合适不过:
- 降低并发成本(直接把协程当作低成本的线程)
- 不用打散业务逻辑
- 心智负担低
几种后端模式对比
server任务(并发):
监听等待tcp长链接 -> client 上传文件 -> 从conn fd 不断读数据流 -> 保存到本地 -> 写一条数据库- 协程实现(go语言为例):直接一个连接一个协程,按“阻塞”方式写逻辑,得到的就是全程“非阻塞”的代码,go runtime 来负责调度
- 多线程实现:一个连接一个线程,按阻塞方式写逻辑,同样是逻辑不被打散的代码,os 来负责调度
- event-loop(io multiplex):一个链接对应一个fd,监听所有fd上的io事件,在事件循环中处理每个事件,循环中不能阻塞(不是不能,是阻塞了就没有意义了),无调度开销
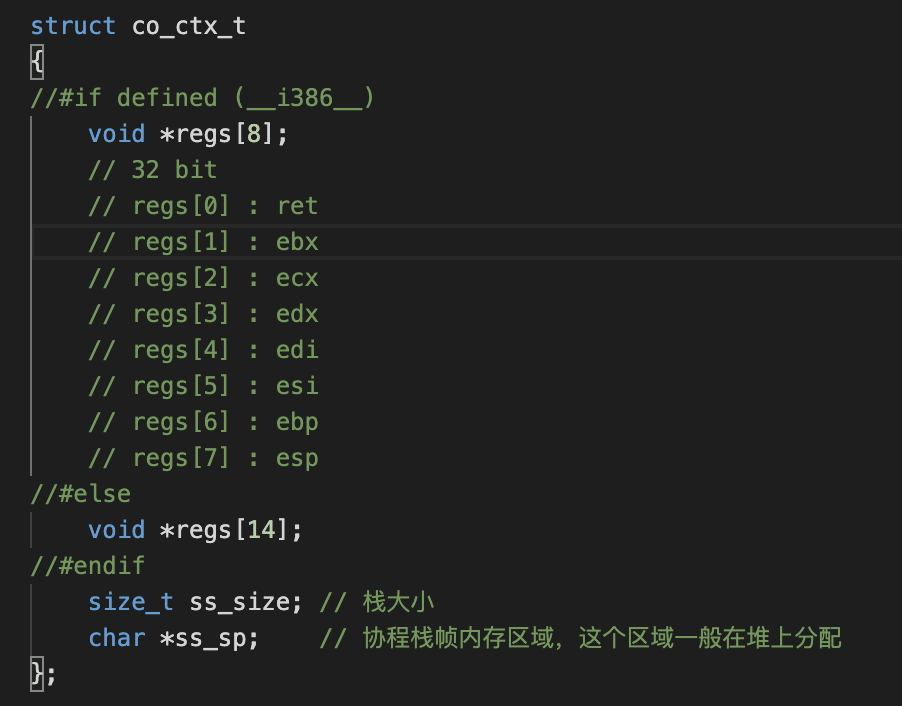
几个寄存器和指令(x86)


x86:
%cs:%ip 永远指向下一条指令
%esp 栈指针寄存器
%ebp 函数调用时用来指示栈帧底部
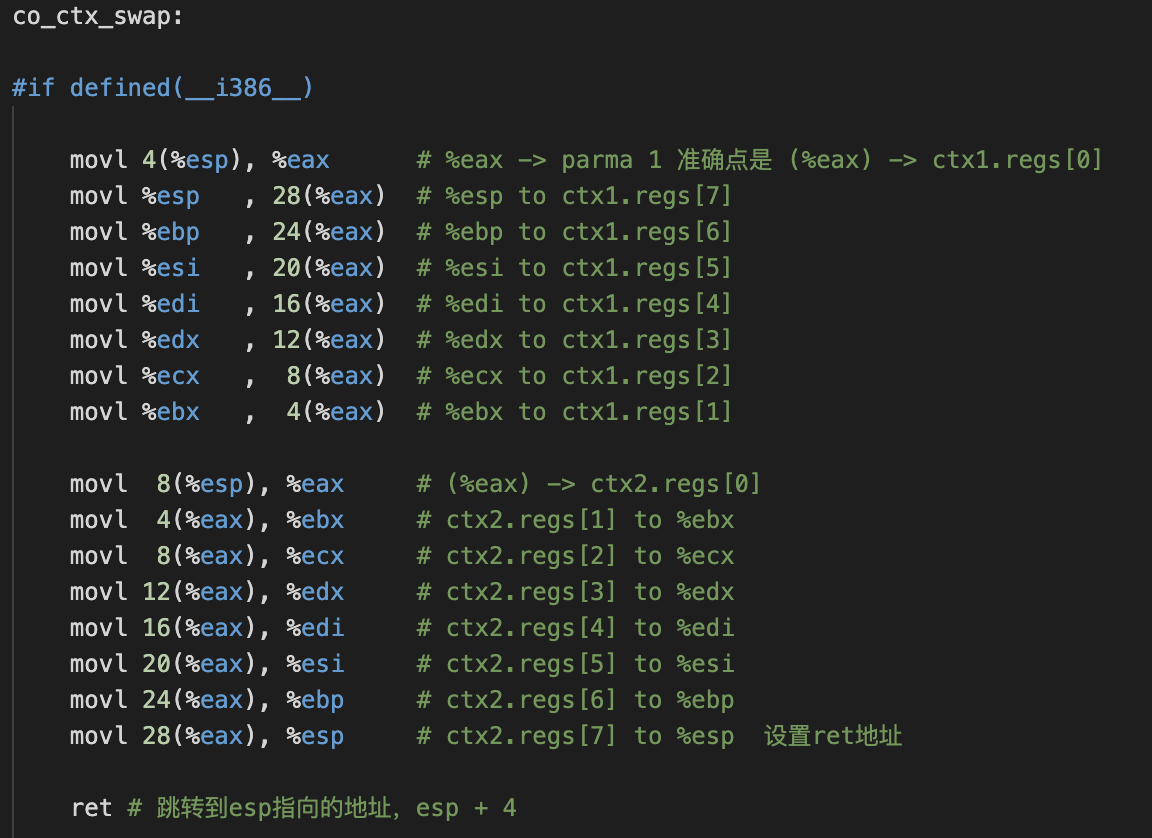
call label 将ret压栈,跳转至label
ret 根据%esp中的地址跳转x86调用过程
以32位系统为例
- 函数压栈,顺序从右到左
call指令ret addr压栈- 修改
cs:ip跳转
- 新函数执行,一些准备操作(处理ebp)
- 执行完成,把返回地址装入 esp
- ret 指令,函数返回到esp指向的位置


一个协程实现
https://github.com/kirito41dd/libco/blob/zsh-dev/src/co_ctx_swap.S
main 0, before switch to hello
co1 hello
main 1, switch back to main
co1 see you again
main 2, switch back to main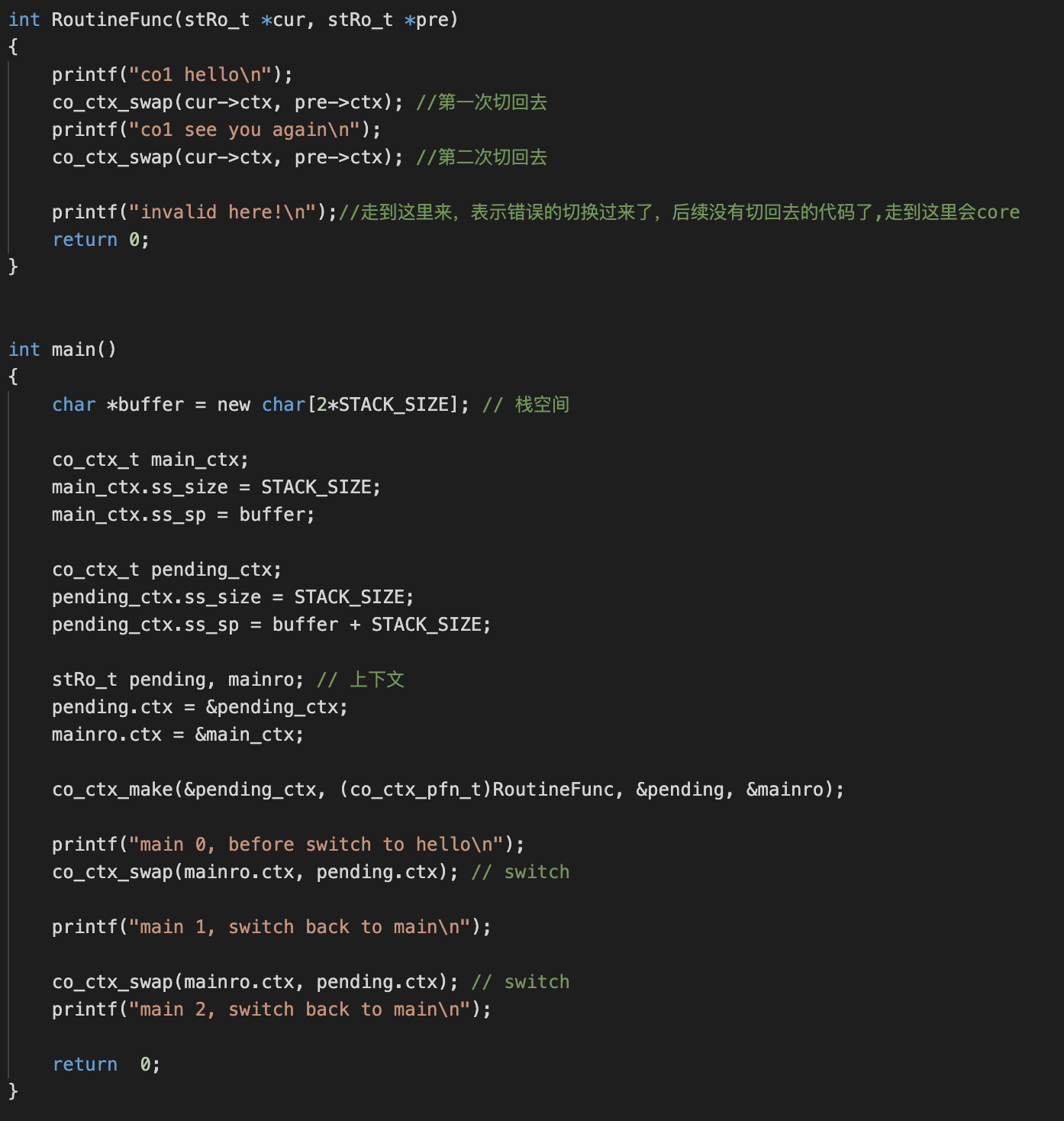

有栈协程 vs 无栈协程
有栈:go、lua、 c 三方库、rust 三方库
无栈:rust、js、kotlin、cpp20